Kafka Consumers
Applications that read data from Kafka topics are known as consumers. Applications integrate a Kafka client library to read from Apache Kafka. Excellent client libraries exist for almost all programming languages that are popular today including Python, Java, Go, and others.
Consumers can read from one or more partitions at a time in Apache Kafka, and data is read in order within each partition as shown below.

A consumer always reads data from a lower offset to a higher offset and cannot read data backward (due to how Apache Kafka and clients are implemented). As we know Kafka topics are divided into partitions. Partitions are the basic unit of parallelism and distribution in Kafka. Each partition is a log of messages, and multiple partitions allow Kafka to scale horizontally by distributing data across multiple brokers and consumers.
If the consumer consumes data from more than one partition, the message order is not guaranteed across multiple partitions because they are consumed simultaneously, but the message read order is still guaranteed within each individual partition.
By default, Kafka consumers will only consume data that was produced after it first connected to Kafka. This means that to read historical data in Kafka, one must specify it as an input to the command, as we will see in the practice section.
Kafka consumers are also known to implement a "pull model". This means that Kafka consumers must request data from Kafka brokers in order to get it (instead of having Kafka brokers continuously push data to consumers). This implementation was made so that consumers can control the speed at which the topics are being consumed.
Consumer Group
Consumers that are part of the same application and therefore performing the same "logical job" can be grouped together as a Kafka consumer group.
A topic usually consists of many partitions. These partitions are a unit of parallelism for Kafka consumers. The benefit of leveraging a Kafka consumer group is that the consumers within the group will coordinate to split the work of reading from different partitions.
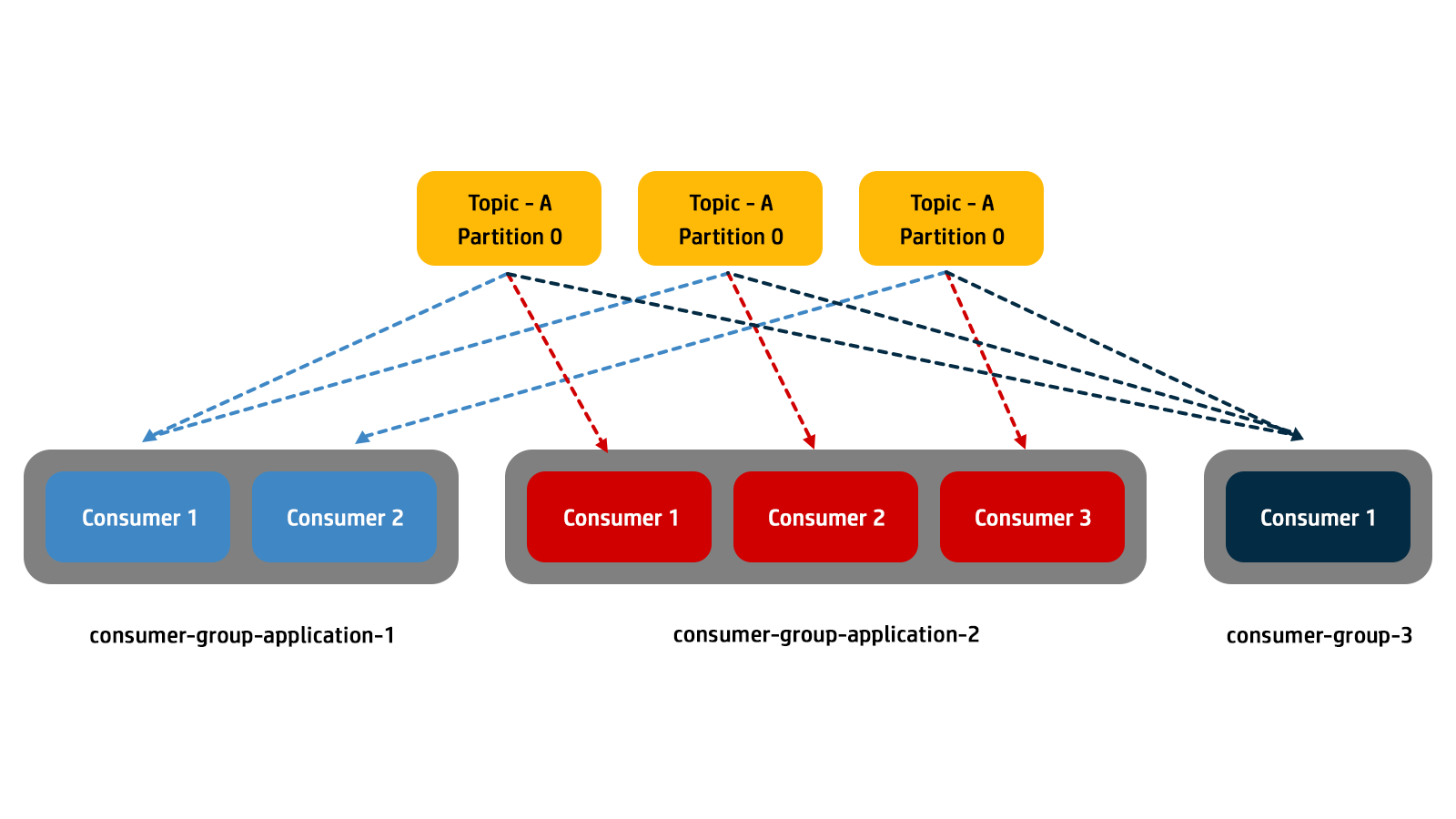
Each partition is assigned to only one consumer within a consumer group. This assignment ensures load balancing and allows multiple consumers to work in parallel, processing messages from different partitions of the same topic.
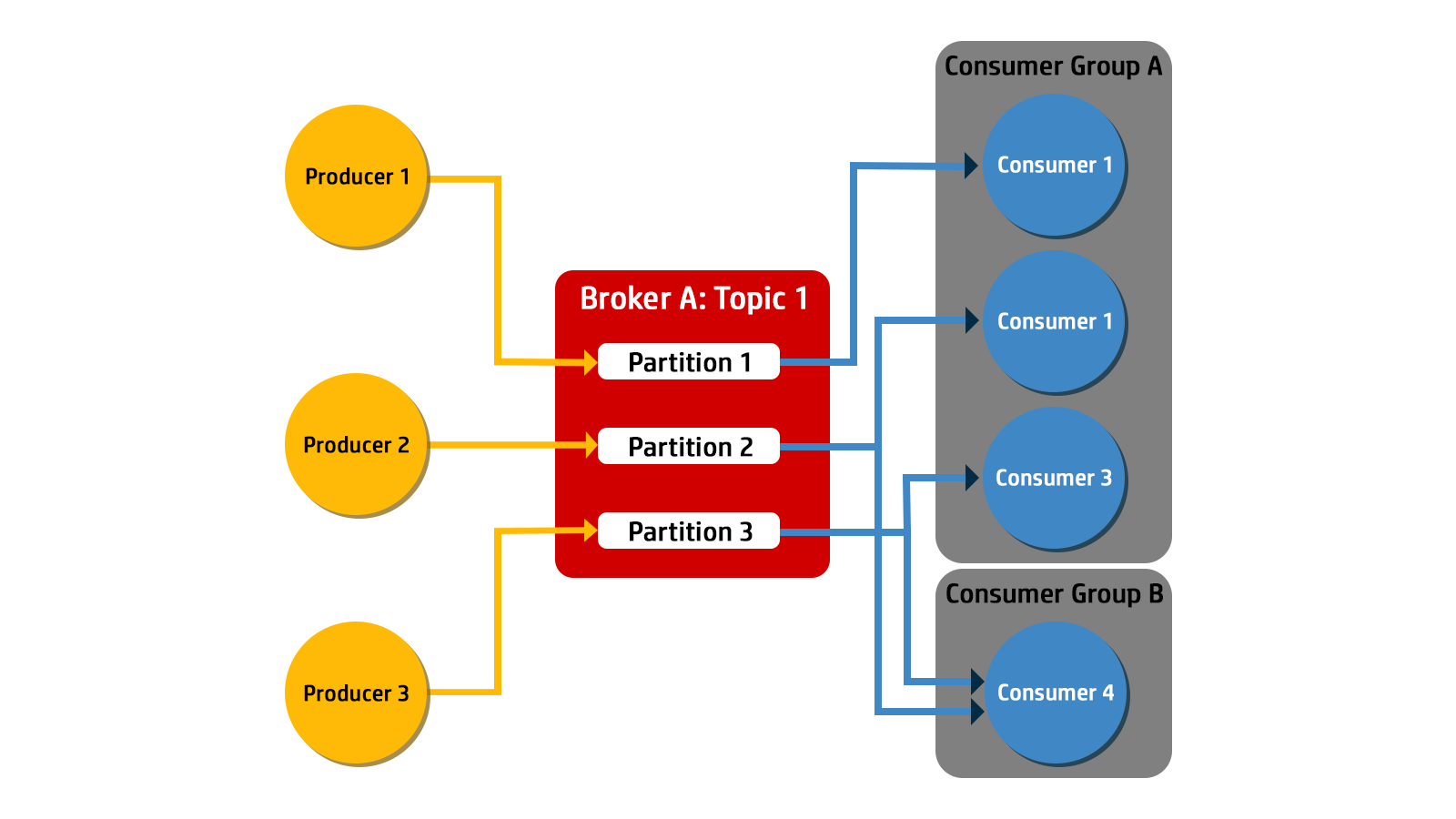
Kafka uses consumer groups to increase scalability.
One or more consumers can belong to a consumer group, with all of them sharing a group ID. If a consumer group has only one consumer, then it is referred to as an exclusive consumer. An exclusive consumer must subscribe to all of the topic partitions it needs. For consumer groups with more than one consumer, the workload is divided as evenly as possible.
Within a consumer group, only one of the consumers will subscribe to an individual partition. In other words, an individual message from a topic is received by a single consumer within a consumer group. Multiple consumer groups can be subscribed to read from a partition at different times.
If a consumer drops off or a new partition is added, then the consumer group rebalances the workload by shifting ownership of partitions between the remaining consumers. A rebalance within one consumer group does not have an effect on any other consumer groups.
The figure below shows how when Consumer 1 in Consumer Group A crashes, the consumer group rebalances the workload to have Consumer 2 receive messages from Partition 1.
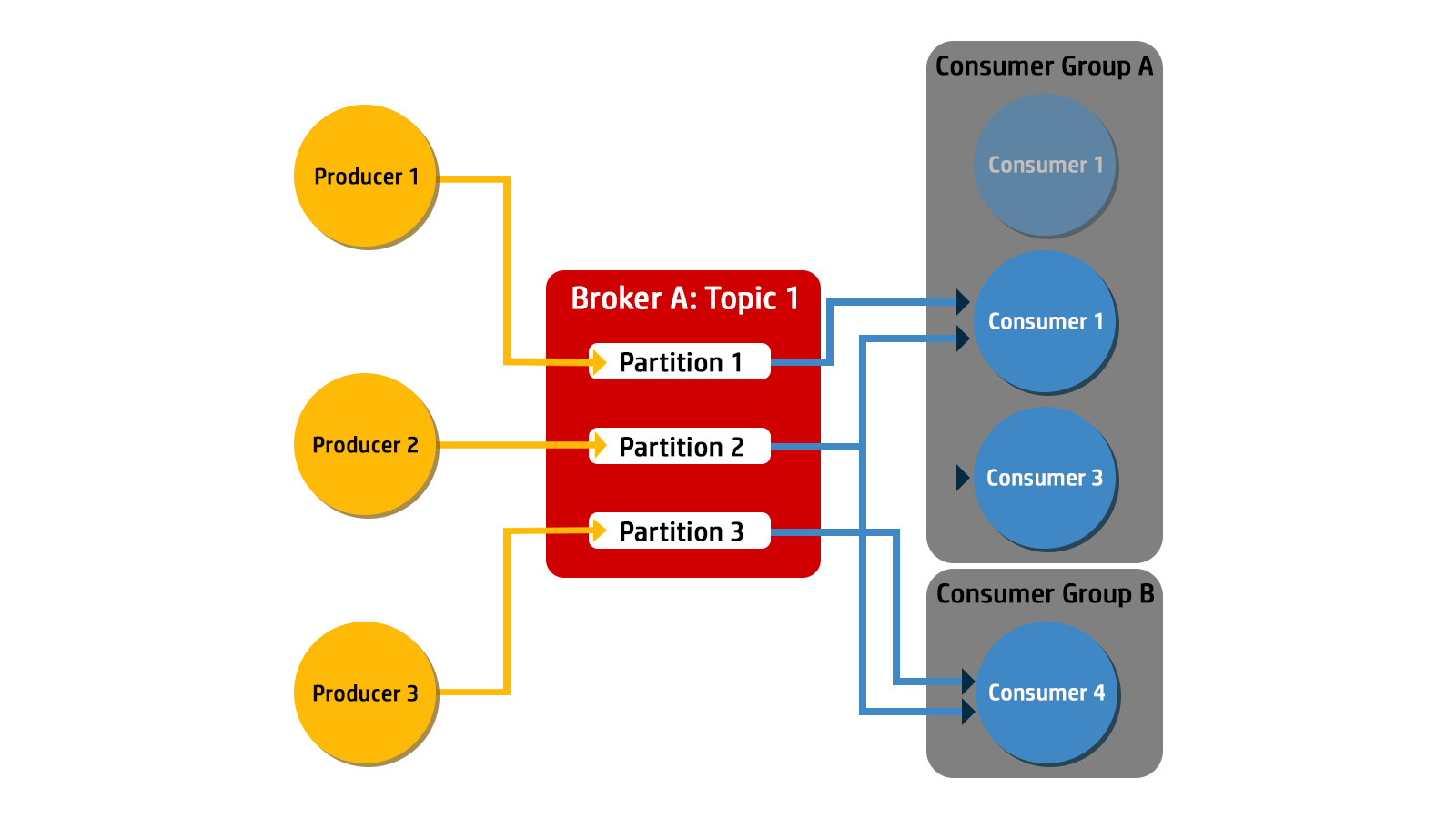
Consumer groups enable horizontal scaling. You can add more consumers to a group to increase the processing capacity.
When new consumers join a group, Kafka automatically reassigns partitions among the consumers, balancing the load.
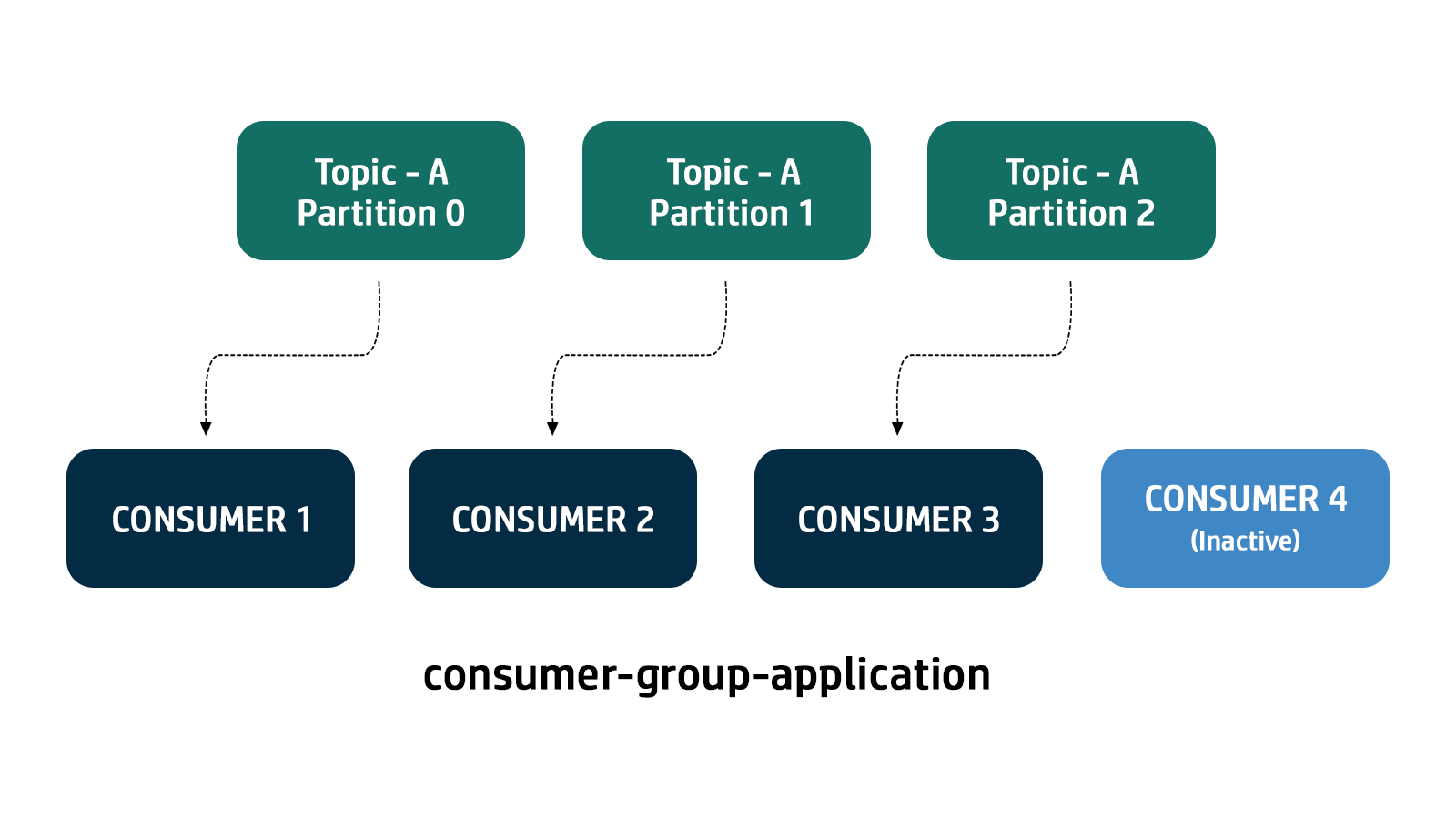
If there are more consumers than the number of partitions of a topic, then some consumers will remain inactive as shown below. Usually, we have as many consumers in a consumer group as the number of partitions. If we want more consumers for higher throughput, we should create more partitions while creating the topic. Otherwise, some of the consumers may remain inactive.
W.r.t Group Coordination, Kafka brokers coordinate consumer groups. When a consumer group is created, one consumer is designated as the group leader. The group leader communicates with Kafka brokers to assign partitions to each consumer in the group. If a consumer fails or leaves the group, its partitions are reassigned to other consumers by the group coordinator.
Consumers can dynamically join or leave a consumer group. This allows for flexible and fault-tolerant consumer architectures. When a consumer joins or leaves, the group coordinator rebalances the partitions among the remaining consumers to ensure efficient utilization of resources.
Regarding Offset management, Consumer groups maintain their own offsets for each partition they consume. Offsets represent the position of the last processed message in each partition. Kafka stores these offsets in a special internal topic called __consumer_offsets.
Consumers periodically commit their offsets to indicate the successful processing of messages. This offset management mechanism ensures fault tolerance and enables consumers to resume processing from where they left off, even after a failure or restart.
In summary, consumer groups in Apache Kafka facilitate the efficient and fault-tolerant consumption of messages. They provide a scalable and parallel processing framework, allowing applications to handle large volumes of data reliably. Consumer groups are a fundamental concept in Kafka, enabling distributed, real-time data processing at scale.

No Comments